Efficiency of Prolog
The key point about Prolog is that the PURE things are fast and the
imperative things are slow, which is the direct opposite of languages
like Pascal. (Richard O'Keefe, Prolog Digest, 1987)
Introduction
Is Prolog fast? Is it slow? Will it be fast enough
for your task? (Most likely: yes.)
Prolog is a programming language, and like for any
programming language, there are many different ways to
implement it. For example, we can compile a
Prolog program to abstract or concrete machine code,
or we can interpret a Prolog program with various
techniques. The most popular implementation technique for Prolog
is compiling it to abstract machine code. This is
similar to the most common implementation methods of other
languages like Pascal, Lisp and Java.
The Warren
Abstract Machine (WAM) is among the most well-known target
machines for Prolog. Other popular choices are the ZIP
and TOAM. Some implementations also compile
to native code.
For example, in GNU Prolog, the
predicate list_length/2
is translated to the following abstract machine
instructions, represented using a
Prolog term:
predicate(list_length/2,5,static,private,user,[
switch_on_term(1,2,fail,4,fail),
label(1),
try_me_else(3),
label(2),
get_nil(0),
get_integer(0,1),
proceed,
label(3),
trust_me_else_fail,
label(4),
allocate(2),
get_list(0),
unify_void(1),
unify_variable(y(0)),
put_value(x(1),0),
put_structure((+)/2,1),
unify_variable(y(1)),
unify_integer(1),
call((#=)/2),
put_value(y(0),0),
put_value(y(1),1),
deallocate,
execute(list_length/2)]).
It is such instructions that are actually interpreted when
you invoke this predicate in any way. In fact,
GNU Prolog even goes beyond this, and further translates such
instructions to native code.
Throughout the following, keep in mind that efficiency is a
property of a Prolog implementation, not of the
language itself!
We distinguish at least two kinds of efficiency:
- space efficiency, denoting how
much main memory (RAM) a program uses
- time efficiency, denoting how long a program runs.
Both kinds of efficiency are of considerable importance in
practice, also when programming in Prolog.
Space efficiency
To understand memory usage of Prolog programs, you need to have a
basic understanding of how Prolog programs are executed. See
Richard O'Keefe's book The Craft of Prolog for a very
nice introduction.
| Video: |
|
The concrete memory usage depends on the Prolog compiler or
interpreter you are using, the optimizations it applies, and
which virtual machine architecture is used.
However, almost all Prolog compilers and interpreters distinguish
at least the following memory areas:
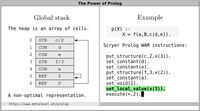
- the global stack, sometimes also called
the heap, copy stack or only
the stack. Prolog terms are created and
stored in this area.
- the local stack, used for predicate
invocations. Stack frames, which are also
called environments, are allocated on this stack to
remember how to proceed after a predicate is invoked. If
multiple clause heads match when a predicate is invoked, then
the system must internally remember this so that it can later
try the alternatives. The system is said to create a
choice point to store this information.
- the trail, used to undo bindings on backtracking.
You can test how your Prolog system behaves when you—for
example—use more global stack than is available:
?- length(_, E), L #= 2^E, portray_clause(L), length(Ls, L), false.
1.
2.
4.
...
16777216.
33554432.
67108864.
ERROR: Out of global stack
Prolog does not provide any means to manipulate system memory
directly. For this reason, large classes of mistakes that are
typical for lower-level languages cannot arise at all
when programming in Prolog. For example, with Prolog,
you cannot double-free a pointer, you cannot access an invalid
reference, and you cannot accidentally write into unforeseen
regions of the system memory. Since you cannot control any
low-level aspects of program execution, the Prolog implementation
must automatically perform some tasks for you.
Prolog implementations automatically apply various optimizations
to reduce their memory consumption. The most important
optimizations are:
- argument indexing of clauses to
efficiently select matching clauses and to prevent the creation
of redundant choice points. You can expect any Prolog
system to index at least on the principal functor of
the first argument of any predicate. Modern Prolog
systems perform JIT indexing to dynamically index
those arguments that are likely most relevant for
performance.
| Video: |

|
- tail call optimization to call predicates without
consuming local stack space if the call occurs at
a tail position and no choice points
remain.
Tail recursion optimization is a special case of
tail call optimization.
Prolog implementations typically apply garbage collection
to automatically reclaim areas of the stack that can be safely
used again.
Time efficiency
The time efficiency of any Prolog program depends a lot on
the compiler or interpreter you are using, and available Prolog
implementations differ significantly regarding performance.
Some Prolog implementors have made heroic efforts to achieve peak
performance in a large number of benchmarks. See for example
Aquarius Prolog
by Peter Van Roy, and his accompanying PhD
thesis Can
Logic Programming Execute as Fast as Imperative
Programming?. Even
today, A
Prolog Benchmark Suite for Aquarius by Ralph Haygood is
frequently used by Prolog programmers to assess their systems'
performance. Some Prolog vendors are prioritizing other features
over performance.
However, a few general points hold for all Prolog implementations:
First, Prolog programs are typically much more general than
comparable programs in other languages. For example, Prolog
implementations support logic variables, which are
much more general than variables in most other programming
languages. In addition, Prolog supports built-in backtracking and
nondeterminism, which also need additional mechanisms. The
overhead of this generality is, in almost all
cases, acceptably small. Look at it this way: If you
need these features, then a roughly comparable
overhead would have been necessary to implement them in other
languages that do not ship with these features.
Second, pure Prolog
lacks destructive updates to terms. For this reason,
implementing (for example) efficient matrix operations requires
special support from the Prolog compiler. Alternatively, at least
logarithmic overhead is necessary to express updates in a
pure way. Prolog programs are efficient under the
so-called tree model of computation. Whether Prolog
programs can be as efficient as possible under the
so-called pointer model is an open research problem.
It is known
that Constraint
Handling Rules (CHR) satisfy this property, so each
imperative algorithm can be implemented with
asymptotically optimal efficiency with CHR.
Third, the choice of algorithm typically has far larger
impact on running time than any particular implementation. You may
make a Prolog program run 10 times faster by rewriting it
in C++, but you typically will not make it 100 or
1000 times faster, for example.
Nevertheless, Prolog is sometimes associated with
being slow. In our experience, the main reasons for
this are:
- Exponential-time algorithms can be conveniently encoded in
Prolog.
- Beginners sometimes accidentally write Prolog programs that
do not even terminate, then call them "slow".
In response to point (1), we can only say that
exponential-time algorithms will eventually turn unacceptably slow
in any programming language, using any
implementation method. Also, many Prolog systems provide built-in
methods and libraries that let you solve large classes
of combinatorial optimization
tasks very efficiently. In practice, the performance of these
specialised mechanisms is often far more important than the
overall speed of the entire system.
In response to point (2), we point to declarative ways of
reasoning about nontermination
of Prolog programs via failure slicing. When you run a
program that is "too slow", first apply this technique
to ensure that the program even terminates, or at
least may terminate.
In general, regarding efficiency, Prolog is at least as acceptable
a choice as for example Python or Java for most projects, and will
typically perform in roughly the same way.
Writing efficient Prolog code
Here are a few tips for obtaining efficient Prolog code:
- Before even thinking about performance, make sure
that your predicates describe only the
intended objects
and terminate for those cases
where you expect them to terminate. When beginners
complain about performance of Prolog, they are typically
writing predicates that don't terminate. Use ?-
Goal, false. to test universal termination
of Goal.
- Delegate as much of the work as possible to the
underlying Prolog engine. For example, if you need
efficient look-up in a database, represent your data in such a
way that the Prolog system's indexing mechanism solves the
task for you. As another example, if you need efficient
search and backtracking, using the built-in mechanisms will
likely be more efficient than formulating the search
within Prolog.
- Always aim for clean
data structures. These let you symbolically
distinguish different cases and make automatic
argument indexing applicable.
- If you cannot use argument indexing, use
if_/3 to
distinguish different cases, preserving generality and
determinism.
- If your predicate depends on the outcome of an arithmetic
comparison between integers,
consider using zcompare/3 to reify the
comparison. This makes its result available as an atom
(<, = or >) which is
again amenable to argument indexing.
- Perform pruning early to
reduce the size of the search space. A simple heuristic
is to place those goals first
that always terminate, such as
CLP(FD) constraints and dif/2.
- Learn more about memoization and
other alternative execution strategies.
- Consider using macros
and partial evaluation to produce
more efficient code at compilation time.
Good performance is often important. However, do not get carried
away with micro-optimizations. For example, leaving an occasional
choice point is often completely acceptable in
user programs. Likewise, reporting redundant solutions is not
inherently bad. For beginners, it is easy to get dragged into
procedural aspects too early. Do not fall into this trap!
Instead, focus on those aspects of your programs where your
attention is most warranted. Let the machine and
Prolog system take care of the more trivial aspects.
Not everything needs to be implemented with utmost
efficiency.
Most importantly: Never sacrifice correctness for
performance! When writing Prolog programs, the most elegant
solutions are often also among the most efficient.
Therefore, when writing Prolog code,
always aim for elegant and general solutions. If they are not
efficient enough even though you have followed the advice on this
page, it may be a sign that you need a new language
construct from which many other Prolog programmers could
potentially benefit too. In such cases, ask the
Prolog community for more information! For example, the
newsgroup comp.lang.prolog is a good place for such discussions.
More about Prolog
Main page